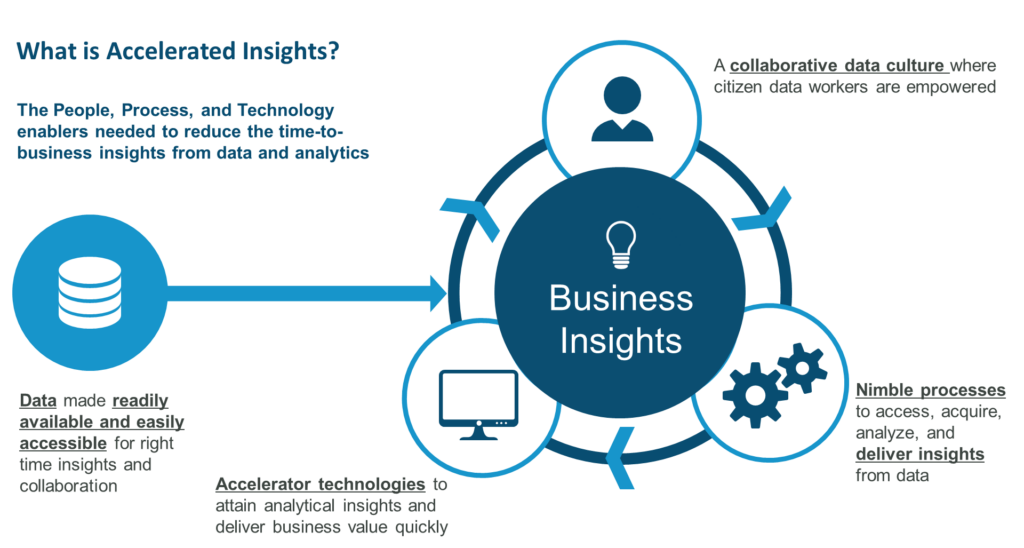
Reduce Time-to-Insights from Your Data & Analytics
Accelerating turnaround time for insights eases internal decision making and adaptability. Using new technology considerations alongside organizational enablements can drastically reduce the time to insights
Today’s savvy citizen data workers need information at their fingertips to make quick decisions in the service of their customers. They simply can’t wait months or even days for a table, dashboard, analytic, or report to be created. Fortunately, modern business and data architectures are adapting, and technologies innovating, to meet these needs for accelerated business insights from data and analytics.
Achieving Accelerated Insights: Data & Technology Considerations
Adaptive & Agile Data Architectures
Today’s modern data architecture needs to be adaptive to the diverse needs of the citizen data worker community – advanced analytics, exploration, visual storytelling, etc. – all, while reducing time to insight (or value). This is where a multi-faceted, needs-driven modern data architecture comes into play. Note that although the data and analytics world is changing at a feverish pace, the usual culprits are still key components to this modern architecture – after all, they were created for a reason.
Yes, we’re talking about data lakes and data warehouses. Though there has certainly been no shortage of attempts to create new naming or buzz words for these items, it’s really the evolution of how these components are combined and used to accelerate business value for different segments of the citizen data worker community that is the key to the modern data architecture.
The Adaptive Data Lake
In its simplest form, a data lake is where data can quickly be landed in its raw (or close to raw) state. The term quick is key here as there is limited time spent to understand and transform data upfront. This component of the modern data architecture is essential for advanced analytics and accessing data, even before much of its value is known. This layer of architecture is primarily the playground (or proving ground) for data scientists to run machine learning and other advanced statistical models, i.e., uncover correlations and future-focused insights and predictions.
A well-implemented adaptive data lake provides the ability to quickly provision sandbox environments. These sandboxes enable data scientists and other power users to perform analysis across varying data sets without waiting for the full data modeling and integration that is typically necessary for broad organizational consumption. In addition, as value becomes known, this layer acts as the source for the data warehouse.
Enterprise data warehouses have been prevalent in organizations for several decades and still exist today. The data warehouse has gotten a bad rap in recent times due to the perception (and expectation) of long cycle times for data preparation – prior to any business access to the data contained within. In a modern data architecture, the need for curated data to enable the business is still absolutely critical, but the construction of those pipelines can happen much faster with accelerator technologies (we’ll discuss this concept further below).
The technologies to build data into the data warehouse much faster, paired with the enhanced and automated features of augmented self-service tools, enable insight and value extraction from the enterprise data warehouse to happen much quicker than traditional methods. The now-quick business insights attainable from the agile data warehouse for analysts is a compliment to the expedited ability to mine raw data for advanced analytics that the adaptive data lake provides to data scientists.
The Integrated Data Hub
The concept of a data hub aligns with the objective of modern data architecture to reduce time-to-insight (and time-to-value) from data. A data hub is the connection point between different data environments, applications, and processes. It provides translated and (typically) standardized data for efficient data interchange across the organization.
Data hubs enable the data fabric of an organization by facilitating the efficient transfer of high-quality, standardized data across an organization’s data highways. Master data hubs are a good example of this concept. Though not typically end-user facing, this architectural component is essential to interfacing data between data lakes, data warehouses, and the enterprise application architecture in a streamlined manner. The more frictionless that data can move within an organization, the faster high-quality data can be made available for insights and to support operational processes.
The Intelligent Data Catalog & Marketplace
In addition to making “blessed” data sets available for broader organizational consumption, the intelligent data catalog, paired with the data marketplace, drives data understanding and sharing between individuals and business units. Enabled by AI, data is found, rated for quality, given business and IT context, and made accessible for anyone to use (within privacy guidelines and security policies, of course). Users can rate data for its usability, access data posted by others, or post data they think would be helpful to others. This construct allows for quick and easy access, understanding, and usage of valuable data across the citizen data worker community.
The above architecture components, working in complementary coordination, all help to reduce the time-to-insight and value of organizational (and external) data and analytics.
Data & Analytics Technology Accelerators
Now that we’ve discussed the modernized adaptive and agile data architecture that can reduce time-to-insight from your data and analytics, let’s discuss how technology can further accelerate getting the right insights – into the right hands – in the right business moment. Below are technology accelerators to consider for expediting data flow and value.
Augmented Self-Service
Quickly dwindling are the days when end-users were asked to explore data and find insights on their own via inflexible dashboards. As stated by Gartner® in their post titled, Gartner Top 10 Data and Analytics trends for 2021, “Gartner believes that, moving forward, these dashboards will be replaced with automated, conversational, mobile and dynamically generated insights customized to a user’s needs and delivered to their point of consumption.”[1]
The rise of the “augmented consumer” is driving a need for more AI-powered technologies to be embedded in vendor self-service tools. Examples of AI capabilities include conversational natural language querying (NLQ), dynamic data storytelling, and intelligent visualization.
Now, less-than-technical users can be automatically presented with data in a business context, and with insights generated through self-learning models. This can drastically reduce the time an end-user might spend dredging through data, associating, and extracting potential insights. It can also present insights that an end-user may not have found through their own cognitive discovery efforts. Examples of these technologies include Tableau’s Ask Data and Explain Data, Power BI’s Q&A, and Qlik’s Cognitive Engine and Associative Engine.
The evolution of data science enablement tools provides a head start to organizations looking to accelerate their advanced analytics journey and drive their business forward – even without a bench of expert data scientists. These technologies come with pre-built Machine Learning models that can be quickly evaluated using Automated Machine Learning (AutoML) to determine the best fit for the specific data set and use case.
In addition to expediting the feature selection, engineering, and model execution, automated analytics tools can also speed up the arduous process of data preparation – from automated column classification (e.g., type, intent, statistical application, etc.) to intelligent mapping. Examples of these technologies include DataRobot, Azure ML, Databricks, and BigSquid.ai.
Data Pipeline & Warehouse Automation
Initially intended to ease the burden of long cycle times for ETL development and data warehousing, automation technologies surfaced leveraging metadata to drive the automated provisioning of data objects (think DDL). These tools have expanded to include automated ETL/ELT engineering, data lineage capture (and visualization), source data discovery, source to target mapping, testing, monitoring, etc. All of these tasks that have traditionally taken data engineers and data management teams long cycle times to get right (which is a primary reason why data warehousing has gotten a bad rap in recent times), can now be done in hours or days vs. weeks or months.
Also, these are not only reserved for data warehouses but can be leveraged on data lakes and other data stores as well – whenever there is a design pattern at play. Note that many of these tools are now available with low code environments in addition to scripted. Examples of these technologies include TimeXtender, WhereScape, Qlik’s Compose, as well as other open-source frameworks (e.g., dbt, etc.).
Enjoying this insight?
Sign up for our newsletter to receive data-driven insights right to your inbox on a monthly basis.
Accelerating an organization’s value potential from data requires implementing technologies that align with business skills and desires; establishing processes to improve business/IT collaboration; and enlisting the business in driving value from data assets.
Below are three approaches that promote partnership between business and IT stakeholders to expedite data-driven value.
DataOps
DataOps is a collection of people, processes, technology, and data that strives to break down barriers between different groups responsible for the delivery of data and analytics. The premise of DataOps is Agile delivery and more inclusion of the business during the development process.
Traditional waterfall delivery of data and analytics still persists partially due to the serial nature of delivering datasets, reports, and analytics, i.e., you can’t deliver a report without first giving the report data. In DataOps, business SMEs, data analysts, data engineers, QA resources, and data scientists are all included in delivery cohorts to more efficiently move work from concept to completion. The use of technology to automate the discovery and resolution of data quality issues has the added benefit of keeping valuable resources out of troubleshooting and instead focused on value delivery.
Lastly, continuous integration and delivery concepts are utilized to allow multiple teams to execute in parallel and to leverage shared code from centralized repositories. All of these components converge to more efficiently deliver key business insights while also optimizing the use of an organization’s technical resources.
Data Literacy
IT and development resources are oftentimes bogged down with data quality inquiries and questions about data or analytics from the business that can be self-served with the appropriate tools and data literacy. These inquiries take valuable resources away from fulfilling critical data and analytics requests for the business.
Data literacy helps organizations speak a common language and develop a foundational understanding of data sources, datasets, systems, and tools available for use. Resources such as user groups, data academies/badges, short-format videos, community support channels via Slack or Microsoft Teams, and metadata technologies (e.g., Data Catalogs) provide a rich base of knowledge and tools for the end-user community. The goal of this is to drive more value from an organization’s data by getting more of the organization in the game. It also helps to decrease the demand on IT and data delivery teams by enabling end-users to self-serve when questions, issues, or new needs arise.
Data literacy is often overlooked as most organizations focus on building and delivering data and analytics solutions accompanied by single-purpose end-user training for those solutions. Achieving data literacy should be a priority for any organization that wants to optimize business value from data assets rich with potential.
Business Driven Architecture
As highlighted earlier in this article, building a robust and powerful data architecture is now table stakes for competing in today’s data economy. Too often, data architectures are built from the technology up and lack a focus on end-user needs and wants. Scalability, redundancy, and performance are all valid and noble goals for a data architecture, but in a vacuum, they alone don’t typically deliver optimal business value. Understanding business skills, needs, desires, and preferences is critical in designing a data architecture that will enable the business to become frequent and powerful citizen data workers – and in turn, extract value from data.
It’s typically insufficient to implement a data visualization or exploration tool like Tableau or Microsoft Power BI alone. In addition, diverse data assets in raw form, semi-structured and structured forms should be made available to business users for easy consumption. Reusable code that has been blessed by IT should be deposited in repositories that data scientists and analysts can access in their pursuit of business-critical insights.
Lastly, data governance tools and disciplines such as master data management, data cataloging, data lineage, and data quality should be implemented to ensure that with greater access given to the business, the quality of insights delivered doesn’t diminish. These data governance tools also have the added benefit of helping the business self-serve while reducing data quality issues – issues that tend to require time from technical team resources to resolve or explain.
Organizational success with data requires intention, commitment, and collaboration from both IT and the business. The above recommendations and approaches are proven ways to accelerate insights and derive value from data and analytics. These considerations also help mitigate common pitfalls associated with monolithic data architectures and associated processes – pitfalls that today’s agile and customer-centric organizations simply can’t afford to be mired in. Is your organization ready to achieve accelerated insights that enable the responsive, agile, and data-driven enterprise?
Contact us to talk about how your organization can achieve reduced time-to-insights from your data and analytics.
Pero Dalkovski and Ian Foley lead RevGen’s Analytics & Insights practice. They are passionate about driving business value from data and have spent their careers helping clients develop the capabilities to do just that.
RevGeneration closes the revenue intelligence gap by finding exactly where your revenue opportunities hide and implementing solutions that deliver real results.