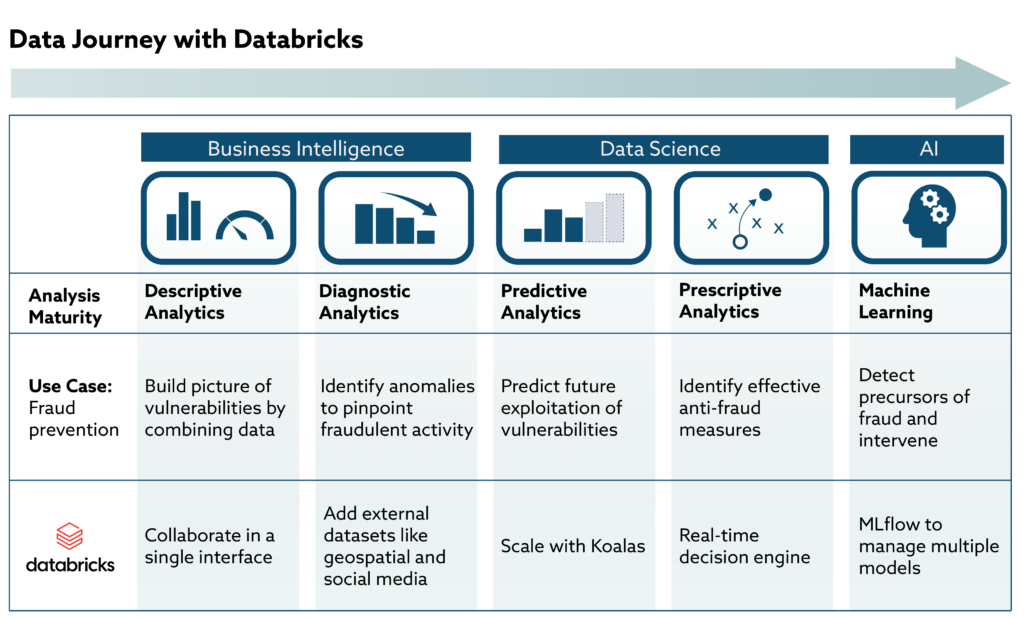
No organization moves from pivot tables to automated machine learning overnight. Pulling value from data takes time and sustained investment. Choosing the right tools up front can speed that journey, saving millions in the long run. Organizations should consider Databricks among those tools.
Databricks is the backbone of some of the world’s most demanding Artificial Intelligence successes. Fortunately, it’s also versatile enough to support the needs of a nascent data science team outgrowing Excel. The software grows with an organization, providing powerful collaboration tools at the onset and delivering superpowered analytics as organizations’ needs grow.
Getting moving with Data Science
Moving, storing, and transforming data is costly and offers no value by itself. Value comes when the right people use the data to answer key questions. Databricks can move organizations down this path more quickly by reducing data engineering overhead. The software is web-based and easy to initiate. This means a data team can start digging for insights quickly without weeks or months to build a backend architecture that delivers the data. (A quick startup assumes data is reliable and available. If that is not case, step one is implementing data governance.)
For organizations that already have cloud-based infrastructure, Databricks is integrated with Azure and AWS. This makes set-up even easier.
Users can aggregate and analyze data using the language they prefer. The software accommodates SQL, the worldwide standard for pulling information from structured databases. It works with Python, R, and Scala, the go-to languages for data science. And it handles Java alongside a host of frameworks and libraries that together comprise the toolkit of the world’s data scientists.
Databricks offers a free community edition, though most organizations will outgrow the free tier quickly. Pricing, like most cloud computing resources, is based on use.
Easy collaboration
Databricks uses a notebook interface. Virtual notebooks are fast becoming the go-to format for collaborative coding in data science. Notebooks display both the input (code) and the output below in the same document. If an analyst writes the code to display a bar chart, the chart appears below the code. Notebooks allow for copious comments, text explanations, and other information that makes it easy to share with colleagues the logic behind computations. The same notebook will support several different languages allowing users to write the logical flow of a data science experiment in the same document.
Without the notebook interface, a user would have a SQL script to pull data, a different script in a different file in a different language to clean the data, and yet another to analyze the data and display it. The process would run across several programs. And the output would be detached from the code. It would be incomprehensible to anyone aside of the code’s author.
The business world is too complex for one-person teams. High-value insights require multi-disciplinary teams that can work quickly, prototype, experiment, and adjust together. Notebooks help this process by laying out what everyone is doing in a clear, easy to follow format.
Technological scaling
An organization’s data analytics journey typically doesn’t start with petabyte-scale datasets, but the tools should never be a bottleneck when big data gets bigger.
Size-wise today’s data quantities put the big data of the past decade to shame. Storage is ubiquitous allowing us to consume (and generate) billions of bytes per day. As organizations’ data grows to petabytes (equal to 1.5 million CD-ROM discs), data processing software needs extra muscle. Databricks was built for this purpose.
The cloud-based infrastructure behind Databricks pulls its computational power from distributed processing. Imagine a large computing task as counting a jar full of jellybeans. Even the world’s fastest jellybean counter is no match for a team of 20, 30 or 40 counters who can split the jar, count their fraction, and add the results. Databricks can assemble an army of counters to tackle massive piles of data and disperse when the job is done.
It seldom makes sense for most organizations to build this kind of computer processing in house. The search for insights is often done on random sample sets, which don’t require rows of servers working in concert. Big computational processes will spin up (and rack up costs) only when needed.
The software includes built-in automation. This lets users implement Machine Learning where new data automatically feeds a model that is constantly refining and improving itself. These are the processes that fuel insights for the world’s most valuable companies.
RevGen has helped countless organizations grow their analytics capabilities through smart investments in people, processes, and technology – including Databricks. We have used the software to solve difficult problems and understand how it can boost the efficacy of organizations at any stage along the journey toward analytics competency.
RevGeneration closes the revenue intelligence gap by finding exactly where your revenue opportunities hide and implementing solutions that deliver real results.