Data is the foundation for modern analytics, including advanced use cases such as reporting, machine learning models and AI enablement. As such, it can be an organization’s most valuable asset, however predictive analytics and modeling tools are only as good as the input data. Poor data quality can lead directly to shortsightedbusiness decisions, missed opportunities, and increased operational costs.
When leveraging data for AI model development, the model’s accuracy, bias, and training efficiency strongly depend on the data quality. Understanding your data, data quality, and its use cases is a critical step toward improving the foundation of your organization’s analytics practice.
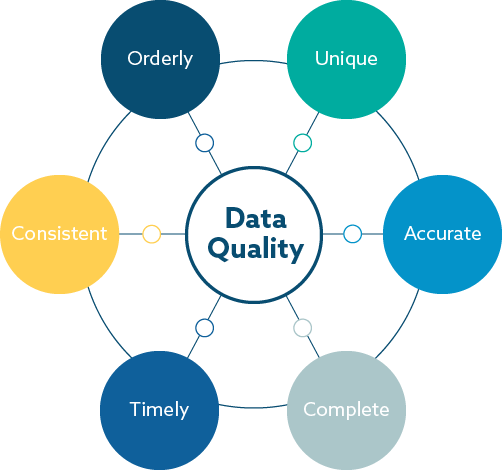
Understanding Data Quality
Organizations collect significant amounts of a variety of data, including transactional and IoT data on day-to-day operations, master data describing the core business entities including customers, products, and vendors, as well as analytic data such as financial metrics and marketing effectiveness. Each of these have a specific purpose and require different management and quality checks to ensure they serve the business effectively.
Regular assessments to identify data issues before they become business compromising should be designed and performed for each data type. This process includes understanding the data’s structure and content, and using key metrics such as accuracy, completeness, consistency, timeliness, and others to ensure the data meets organizational standards. These assessments are ongoing processes that adapt as new data enters and old data evolves. Critical metrics to consider:
Accuracy – Does your data accurately represent reality? Do your calculated measures yield accurate and trustworthy results? Inaccurate data may lead to flawed analyses and misguided decision making such as misallocating resources or poor customer service experiences.
Completeness – Is your data complete with all available information? Incomplete data restricts analytical options leading to poor assessments.
Timeliness – Is your data timely according to standards, and is it up to date with changes? Failure to use real or near-real time data can lead to irrelevant and outdated insights.
Consistency – Is your data coherent and contradiction-free? Inconsistent application of calculations, units, dates or other elements can reduce accuracy and produce conflicting analyses.
Orderliness – Do your data values adhere to a consistent and correct format? Poorly structured or ambiguous data makes interpreting the data more difficult and time consuming.
Uniqueness – Are your data records free from duplicates that might cause errors, including double counting in aggregates? Duplicated values will skew numerical calculations leading to flawed decision making and financial reporting.
Enjoying this insight?
Sign up for our newsletter to receive data-driven insights right to your inbox on a monthly basis.
Organizations seeking to improve their data quality can implement processes and procedures to proactively manage their data. These should be based on the business needs, the end-goals for data consumption, and the nature of the data itself. Here are a few best practices:
1. Define Rules and Metrics: These should be stated clearly and align with the business objectives and data usage scenarios. For example, specify the required accuracy, completeness, timeliness, consistency, and uniqueness of the data for each use case.
2. Implement Quality Checks: Checks and validations should be performed at different stages of the data lifecycle, such as code development, data collection, ingestion, processing, storage, and delivery. Use automated tools and workflows to monitor and report on data quality issues and anomalies.
3. Establish Data Governance: Policies and roles should be defined to ensure accountability and ownership of data quality. Assign data stewards and data owners who are responsible for defining, implementing, and enforcing data quality standards and procedures across the organization.
4. Provide Feedback: Data quality feedback mechanisms and remediation processes are required to enable data consumers and producers to report and resolve data quality problems. These include data quality dashboards, alerts, tickets, and workflows to track improvement actions.
5. Conduct Quality Audits: Regular audits to measure and evaluate the organization’s data quality performance should be performed to identify the root causes of data quality issues and implement corrective actions.
Implementing these initiatives produces value across the business. Operational efficiency and productivity are improved by reducing data errors and waste while increasing data availability and usability. Moreover, data consumers have greater confidence in the insights generated though AI models and these insights yield higher value returns.
Start the Journey to AI Enablement
Implementing the correct data quality measures for your organization requires a strategy that aligns people, process, data, and technology. This holistic and deliberate ensures your organization can efficiently realize the competitive advantage derived from data science, analytics, and AI enablement.
RevGen helps clients build and test their foundational data quality in support of these initiatives. From implementing data governance framework and Master Data Management programs at a global communications company to creating a single source of data truth for a national telecom provider, RevGen works collaboratively with our clients to unlock the value in their data.
Interested in learning more about how RevGen can help you build a foundation of data quality and provide a path to AI enablement? Contact us today to speak to one of our experts.
Michael Nardacci is a Sr. Consultant at RevGen Partners where he works on projects related to business current state assessments and data transformation and migration.
Jeremy Marx is a Staff Engineer at RevGen, specializing in data engineering. He has over a decade of experience building and managing data systems and pipelines on multiple platforms, dedicated to ensuring data consistency that drives meaningful business insights.
AI initiatives succeed or stall based on the quality of the data behind them. The Databricks Data Intelligence Platform is built from the foundation up to address exactly that.
The path to agentic AI isn't a leap—it's a climb built on data quality foundations. Proactive monitoring transforms operations today while enabling autonomous capabilities tomorrow.