As data science continues to play an increasingly vital role in the operations of organizations, the task of implementing machine learning can be quite daunting. Generically, data science efforts follow a methodical process: formulating the hypothesis, deriving a model, gathering data, applying the assertion, followed by questioning the outcome, then rinse and repeat until you have either satisfied your supposition or have exhausted all your resources.
However, there’s been a tremendous leap in the advancements for developing machine learning technology, not just in process improvements but reducing the amount of “code” required for machine learning (ML). Many prominent cloud providers have introduced platforms and services that simplify the process of machine learning by utilizing “low-code” or “no-code” approaches. They now present a concerted effort to enable what we’ve termed “the citizen data scientist.”
This paper looks at the basic steps to create a framework for Low-Code/No-Code Machine Learning using newly introduced processes and services in the Azure and Amazon Cloud.
Low-Code/No-Code Machine Learning in Practice
Cosmo G. Spacely, President and CEO of Spacely Space Sprockets, yelled, “Jetson! Where are my sales forecasts!” In response, poor George sprang into action, keyboard clattering, tossing papers high into the air, and messaging Jane that he’d be late getting home. While times have changed since 1962, the scenario remains familiar. Only today, Judy Jetson is head of Data Science at Spacely Space Sprockets, and this virtualized global company has employees disbursed across numerous time zones.
Like her father’s 1962 effort, Judy’s task is to produce actionable reports based on trends observed from her data science models that run against petabytes of structured and unstructured data hosted in the cloud.
Today, Judy uses the latest tools and processes available on the Cloud but she’s also applying her low-code and no-code principles to her data science efforts. Judy won’t miss any baseball games, nor will she fret over her models and their complexities to best confidence scores. Judy’s tasks are to (1) derive a model, (2) gather data, (3) apply the assertion, (4) followed by questioning the outcome – all while using the Low-Code/No-Code principle.
Let’s take a moment to break down the term “Low-Code/No-Code”. Wiki defines Low-Code as a development platform environment that creates application software through a graphical user interface. No-Code is similar; however, no-code development platforms require zero code writing, generally offering prebuilt templates so businesses can build apps.
Thus, a Low-Code/No-Code MLFlow framework combines data wrangling with data science and produces the encapsulated data science container. A Low-Code/No-Code MLFlow Framework has the ability to perform additional cycles of ML modeling using parameterized variables until we have met the acceptance objectives. After testing and validation, a framework pipeline creates a packaged model deployable to cloud serverless containers.
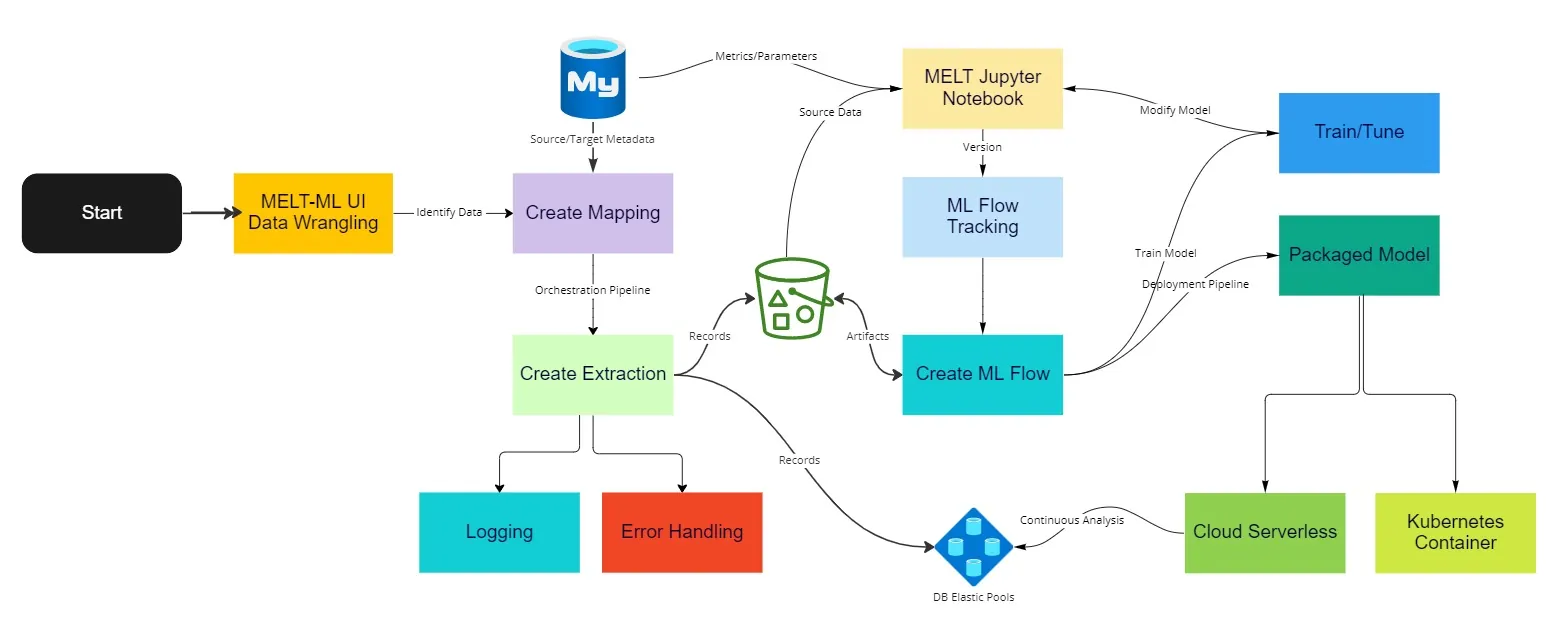
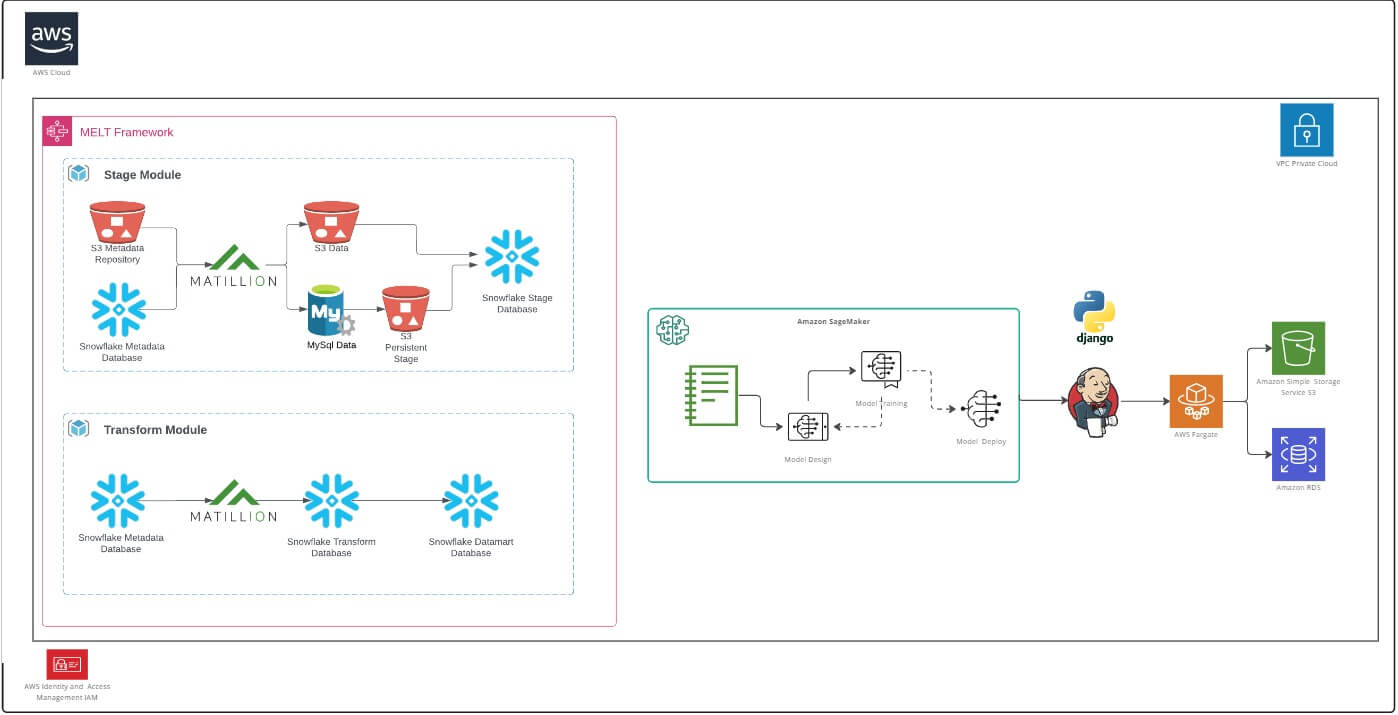
RevGen has developed a solution framework for machine learning that combines data wrangling in the data science arena, where Metadata drives the Extract, Load, & Transform (ELT) processing model, a.k.a. MELT.
MELT uses generalized data flow patterns for nearly all its pre-packaged ELT code, treating every source, target, or extraction rule as a metadata variable. The RevGen approach encapsulates Data Pipelines and Deployment Pipelines reducing the amount of code required to push a model into production.
Click to enlarge
How does “Low-Code/No-Code” apply to data science in the cloud?
Cloud providers like Microsoft Azure and Amazon AWS offer deployable MLFlow cloud services, complete with User Interfaces that visually connect data sets and modules on an interactive canvas to create machine learning models. Thus, the Cloud UI Designer gives you a visual canvas to build, test, and deploy machine learning models.
Key to this process is that these services are not just applying the assertion but running multiple models in parallel to evaluate their performance to achieve a higher confidence number to ultimately shorten the “time to outcome”.
Amazon recently introduced several new services for Low-Code/No-Code that pertain to enhancing ML, including AutoPilot (within SageMaker) that iterates different models to find the best fit. They’ve also enhanced SageMaker with Data Wrangler as a means for easing the required efforts for building data sets. Likewise, Azure has released enhancements to its Automated ML and Designer UI based on Low-Code/No-Code principles.
Click to enlarge
The RevGen Approach
Judy isn’t done, though! She’s engaged RevGen Partners and their Data Science team.
First, RevGen aligns with Ms. Jetson’s business objectives and priorities. Then, we assess Spacely’s cloud deployment to determine platform readiness and cloud needs. Next, RevGen rolls out their “Low-Code/No-Code MLFlow Framework.”
This package of solutions and services encompasses a metadata-driven approach for wrangling data. The MLFlow framework can be set up to iterate through any number of machine learning algorithms paired with parameter-driven selections. As a key feature, each iteration analyzes the model confidence score hence the higher the confidence score, the greater the likelihood that the output of a Machine Learning model is correct and will satisfy a user’s request. Once the MLFlow process framework meets the exit criteria defined as a metadata variable, the ML operation completes, transferring its resultant values and datasets to the cloud deployment packages.
All ELT and ML functions, all data, and all processes are defined and deployed on Judy’s cloud provider using Terraform. Her MLFlow operations are built on the “Low-Code/No-Code” framework, using metadata-driven techniques, improving data analysis from source to target throughout the entire data science lifecycle.
To view the seamless integration of these and other cutting-edge technologies in action, contact RevGen Partners for a live demo, or visit our Technology Services page to learn more.
RevGeneration closes the revenue intelligence gap by finding exactly where your revenue opportunities hide and implementing solutions that deliver real results.