How Did Databricks Build a Data Intelligence Platform?
AI initiatives succeed or stall based on the quality of the data behind them. The Databricks Data Intelligence Platform is built from the foundation up to address exactly that.
There is a definition of the word “platform” that means very little. In technology, almost everything is a “platform” these days, with the word stretching to cover everything from a collection of APIs to a cloud vendor’s entire product catalog. So, when Databricks describes itself as a Data Intelligence Platform, it is worth asking what that means in practice, and whether it represents something genuinely different from all the other data “platforms” in existence.
The short answer is yes. And this difference matters a lot.
Most data platforms process your data. They move it, store it, transform it, and make it available for querying. Databricks does all of that, however, it is also designed to understand your data: its structure, its lineage, its relationships, its meaning within your organization. That understanding is what Databricks calls Data Intelligence, and it runs through every layer of the platform from the storage format up through governance, analytics, and AI. Whether that AI takes the form of a machine learning model, an autonomous agent, a natural language interface for your business teams, or the analytical and reporting tools your organization already relies on, it is only as good as the data behind it.
So, how does Databricks approach the problem of data intelligence? And what capabilities does this true platform offer? Let’s take a closer look.
A Governed Foundation That Understands Itself
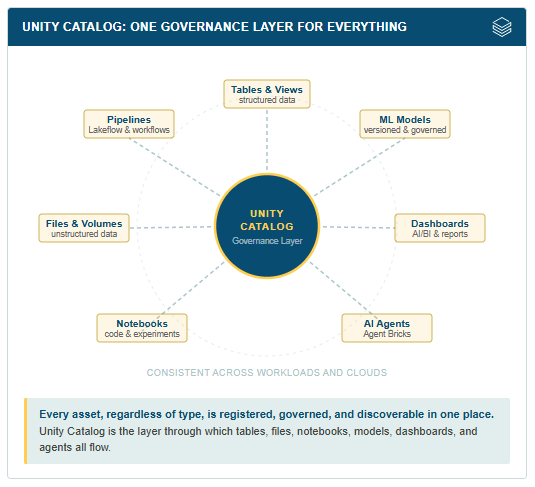
Data intelligence works best when it is built into the foundation rather than layered on top as an afterthought. For Databricks, that foundation is Unity Catalog.
Unity Catalog is the governance layer through which everything on the platform flows: tables, files, notebooks, machine learning models, dashboards, AI agents. Every asset, regardless of type, is registered, governed, and discoverable in one place across workloads and clouds. Well-governed data is also, not coincidentally, data that AI systems, analytical platforms, and reporting tools can trust and reliably use for reasoning.
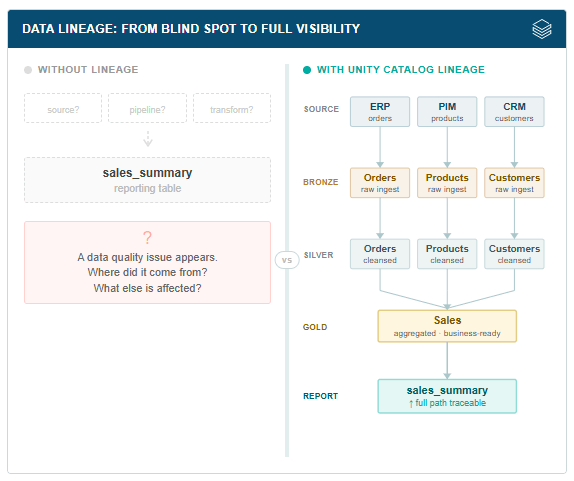
One of the more concrete expressions of this is data lineage. Unity Catalog tracks, automatically and in real time, the full chain of transformations any piece of data has undergone. Consider what that visibility enables:
A compliance team can trace exactly which source systems feed a regulatory report and when each was last updated.
A data engineer debugging a quality issue can see that a column in a reporting table flows from a specific ingestion job that was modified two weeks ago.
When a table is slated for deprecation, the platform makes it straightforward to surface downstream dependencies before the change is made.
That kind of contextual awareness is the difference between a platform that holds your data and one that understands it.
That same intelligence shows up in less obvious places too. Predictive Optimization monitors query and data patterns, then automatically manages table optimization activities to improve performance and reduce storage costs. Liquid Clustering continuously adapts how data is physically organized based on actual usage, eliminating the manual tuning decisions data engineers have historically had to make and then revisit as query patterns evolve.
These are not glamorous capabilities, but they reflect a consistent design philosophy: the platform should learn from your workloads and act on what it learns.
Conversations with Your Data
The most visible face of data intelligence for most business users is AI/BI Genie. Genie lets users ask questions of their data in plain language and receive answers as a combination of text, tables, and visualizations.
Natural language query tools have been around for years, however, there is an important distinction in how Genie works. It does not build an internal model of your data’s content and then approximate answers from that. Instead, it uses its understanding of your table structures and the metadata in Unity Catalog to generate SQL queries that run directly against your actual data.
The answers come from real query results, not from inferences. Ask the same question against the same data, and you get the same answer.
Enjoying this insight?
Sign up for our newsletter to receive data-driven insights right to your inbox on a monthly basis.
This matters because it means Genie’s accuracy is grounded in governance. The better your metadata, the better Genie performs. When a sales manager asks, “how is our pipeline trending by region,” Genie is not guessing at what “pipeline” means based on the average user expectation. It knows because the platform knows your data.
Databricks One, which became generally available in February 2026, extends access to these capabilities well beyond technical users. Business teams across finance, marketing, operations, and executive functions can work with Genie spaces, AI/BI Dashboards, and custom Databricks Apps through a purpose-built interface, with no exposure to clusters, notebooks, or query editors.
The value of data intelligence scales with access. When insights are no longer bottlenecked through a small team of analysts, the platform starts to deliver differently across the organization.
Agents Built on Your Terms
Agentic AI has become one of the more overloaded terms in the industry. At its most useful, it refers to AI systems that carry out multi-step tasks autonomously, taking action, checking results, and adjusting course without requiring human intervention at each step. What separates genuinely useful agentic implementations from hype is whether the agents are fine-tuned in your organization’s context or are simply general-purpose models with a workflow layer on top.
Agent Bricks, which reached general availability in 2025 and 2026, is built around the former. Unlike most agentic implementation, it is not a catalog of pre-built agents you pick from and configure. Instead, it is a development platform for building agents that are specific to your organization’s tasks, grounded on your own governed data, and continuously evaluated against benchmarks that reflect what good performance looks like for your specific usage.
The development process works like this:
You describe the problem the agent needs to solve and connect your enterprise data as the training source.
Agent Bricks automatically generates domain-specific synthetic training data and task-aware evaluation benchmarks tailored to your use case.
The platform optimizes the agent for both quality and cost, running evaluations continuously rather than leaving that burden on your team.
The result is a production-ready agent that reflects your organization’s specific knowledge, terminology, and logic.
For more complex orchestration, the Supervisor Agent pattern allows multiple specialized agents to coordinate tasks that no single agent would handle in isolation. For example, a financial services firm might deploy separate agents for research, risk assessment, and compliance review that work together on a single complex request. Throughout all of this, Unity Catalog’s governance remains in effect: agents operate on data they are authorized to access, and their activity is auditable. The intelligence is customizable; the guardrails are mandatory.
A Data Intelligence Platform that Learns What You Teach It
Here is where it is worth being direct: Data Intelligence is built in, but it is not self-sufficient.
The platform is a fast learner, but it learns from what you give it. The difference between an implementation that delivers real intelligence and one that underperforms often comes down to how well the data and its metadata have been curated by the humans that manage it.
Among the capabilities Unity Catalog provides for this purpose, a few are worth highlighting:
Table and column comments give the platform natural language descriptions of what each data asset represents. Databricks can suggest AI-generated comments as a starting point, but these should always be reviewed by someone who knows what the data means in your unique business context.
Governed tags classify data by sensitivity, domain, or ownership, and they cascade through the object hierarchy. Tag a catalog or schema, and everything beneath it inherits that classification, making it possible to manage access and compliance at scale.
Unity Catalog Metrics define business concepts like revenue, active users, or conversion rate as governed, reusable assets at the data layer. Every team, tool, and AI model on the platform then calculates those numbers from the same approved definition.
For Genie specifically, there is an additional curation layer available through its knowledge store. A Genie space can be configured with example SQL queries for common questions, column synonyms, join relationships between tables, and domain-specific instructions that reflect the vocabulary and logic your organization uses. The more precisely a space has been curated, the more reliably Genie performs on domain-specific questions that a general-purpose model would have no way to answer correctly on its own.
This is where experienced guidance makes a meaningful difference. Knowing which metadata to prioritize, how to structure a Genie space for a specific business domain, how to build the data pipelines that feed clean and well-described data into the intelligence layer: none of that comes automatically with the platform. It comes from understanding both what the platform can do and how your data actually works.
Organizations that invest in this layer receive compounding returns. Data Intelligence improves with more context, and the more capable it becomes, the more value it delivers back across the organization.
What Comes Next
Databricks has been consistent about shipping capabilities that matter, and the pace has not slowed. One recent example worth watching is Data Quality Monitoring Anomaly Detection, now in public preview, which applies the same intelligence philosophy to data health itself, learning from historical patterns to surface issues before they become problems downstream.
Data Intelligence represents Databricks’ answer to a question the industry has been circling for years: what would a data platform look like if it actually understood the data it managed? The capabilities covered here are the foundation. In upcoming articles, we will explore what it looks like to put these capabilities to work and how organizations can get there faster.
To chat with one of our data and AI experts about how Databricks might be effectively deployed at your organization, contact us today.
Jeremy Marx is a Staff Engineer at RevGen, specializing in data engineering. He holds the Databricks Data Engineer Professional certification and brings extensive experience building and managing data systems and pipelines across multiple platforms, dedicated to ensuring data consistency that drives meaningful business insights.
The path to agentic AI isn't a leap—it's a climb built on data quality foundations. Proactive monitoring transforms operations today while enabling autonomous capabilities tomorrow.
Cloud analytics platforms are transforming financial services through on-demand computational power, operational resilience, and seamless data integration while enabling the next generation of AI capabilities